


چند روز پس از بازیابی اولیهی کلاستر ذخیرهسازی، مشکلات ثانویه کلاستر سبب شد روند بازیابی ابرکها با وقفه و اختلال چند روزهای مواجه شود. در این بخش به توضیح این مشکل و راهحلهای تیم فنی آروان میپردازیم.
حجم درخواست بسیار بالای کاربران همزمان برای بازیابی اطلاعات و بروز مشکلات زیرساختی
روز جمعه ۲۹ اسفند۱۳۹۹، همزمان حجم بالایی از کاربران برای درست کردن فایلسیستم یا پشتیبانگیری دیتا مشغول به کار شدند. بهدلیل مشکلات پیشآمده و ریکاور کردن کلاستر ذخیرهسازی در یک فشار زمانی کوتاه، کلاستر موفق به تهیهی سه نسخه از تمام دادهها نشده بود، همچنین برای ساخت ابرکهای جدید برای انتقال اطلاعات روی آن نیاز به فضای بیشتری بود و در نتیجه باید ظرفیت کلاستری که بهسختی آسیبدیده بود نیز افزایش پیدا میکرد. برای رفع این مشکل، به میزان ۴۰۰ ترابایت دیسک به کلاستر اضافه شد.
تزریق منابع جدید، یعنی وزندهی دوبارهی دیسکها (Rebalance) که سبب درگیری شدید زیرساخت و قفل شدن کلاستر میشود. به همین دلیل، در این روز، وضعیت بحرانیتر شد.
بهطور خلاصه مشکل اصلی کلاستر ذخیرهسازی تاثیر تسلسل دو مشکل ReMirroring-Storm و یک Memory Leak در لایهی نرمافزاری Ceph در شرایط خاص بود که همافزایی آنها سبب به اغما رفتن کلاستر میشد. تعداد بالایی از Placement groupهای کلاستر ذخیرهسازی در حالت خطا قرار گرفتند و میزان سرعت نوشتن و خواندن اطلاعات از سوی کاربران (ابرکها) کاهش و به عدد صفر نزدیک شد.
کلاستر در چنین موقعیتی و در هنگامیکه در حالت ریکاور برای اصلاح وضعیت PGها قرار میگرفت، به دلایلی که گفته شد با flapشدن OSDها (سرویسهای نگهدارندهی اطلاعات) دوباره سبب به اغما رفتن کلاستر و شروع دوبارهی یک چرخه معیوب میشدند.
برای حل مشکل در طول چهار شبانهروز، مجموعه اقدامات بسیاری انجام و درنهایت منجر به احیای کلاستر شد. در ادامه برخی از اقدامات فنی ابر آروان برای حل این مشکل را شرح دادهایم.
ابعاد کلاستر
کلاستر ذخیرهسازی ابر آروان در دیتاسنتر IR-THR-AT1 در شهریور ۱۳۹۶ ایجاد شده است. این کلاستر در طول اینسالها بهبود و بهروز رسانی شده و درنهایت با عملکرد مقبولی در حال سرویسدهی به کاربران بوده است.
زیرساختهای شبکه، تنظیمات سیستمعامل و تنظیمات کلاستر در وضعیت مناسبی بوده است، اما زمانیکه کلاستری با این ابعاد -با ظرفیت ۱.۵ پتابایت و از دسترس خارج شدن حدود ۱۰۰ ترابایت اطلاعات بهشکل ناگهانی- با مشکل مواجه می شود، زمان بسیاری برای رفع مشکل و پایداری مجدد کلاستر نیاز است. مشکلی اصلی تیم ابر آروان، فشردگی بسیار بالای زمانی و تلاش برای حل مشکلات در کوتاهترین زمان ممکن بوده است.
ارتقای زیرساخت شبکه و ارتقای منابع
در نخستین اقدام RAM تمام سرورهای کلاستر ذخیرهسازی شامل MON, MGR, OSD از 128GB به 384GB ارتقا پیدا کرد. موضوعی که میتوان گفت تاثیری اندک روی وضعیت عمومی کلاستر گذاشت. در واقع OSDها به حافظهی بیشتر نیاز نداشتند، آنها فقط به هنگام اختلال (Memory Leak) شروع به مصرف بیشتر میکردند و در کمتر از چند ثانیه تمام Memory موجود را هم اشغال میکردند.
گام بعدی بهینهسازی و بهبود زیرساختهای شبکه بود، تا تمام نودها بتوانند در بهترین وضعیت ممکن با یکدیگر ارتباط برقرار کنند. ارتباط OSDها برای ریکاور کردن، سه حالت مختلف را پوشش میدهد؛ ارتباط بین OSDهای داخل یک سرور، ارتباط بین OSDها بین دو سرور مختلف متصل به یک سوییچ و درنهایت ارتباط بین OSDها بین سوییچهای مختلف که از طریق VPC به یکدیگر متصل شدهاند.
در این بخش ارتباط بین سرورها از 10gbps به 20gbps ارتقا یافت همچنین ارتباط سوییچهای VPC از 60gbps به 80gbps افزایش پیدا کرد. (ارتباط بین سرورها در طراحی کلاسترهای جدید ابر آروان بهشکل پیشفرض 40gbps و ارتباطات آپلینک بین سوییچها 200gbps است)

یکی از نکات بسیار مهم در این وضعیت، شناسایی، تمرکز و کاهش TCP Retransmission در شبکهی سرورهای کلاستر ذخیرهسازی است.
بهکمک دستورهای netstat و sar میتوان وضعیت TCP Retransmission در شبکه را مشاهده کرد، همچنین میتوان همزمان بهکمک IPERF3 یا راهکارهای مشابه، بار شبکه را در حالت بیشینه قرار داد و مجدد وضعیت را مورد بررسی قرار داد:

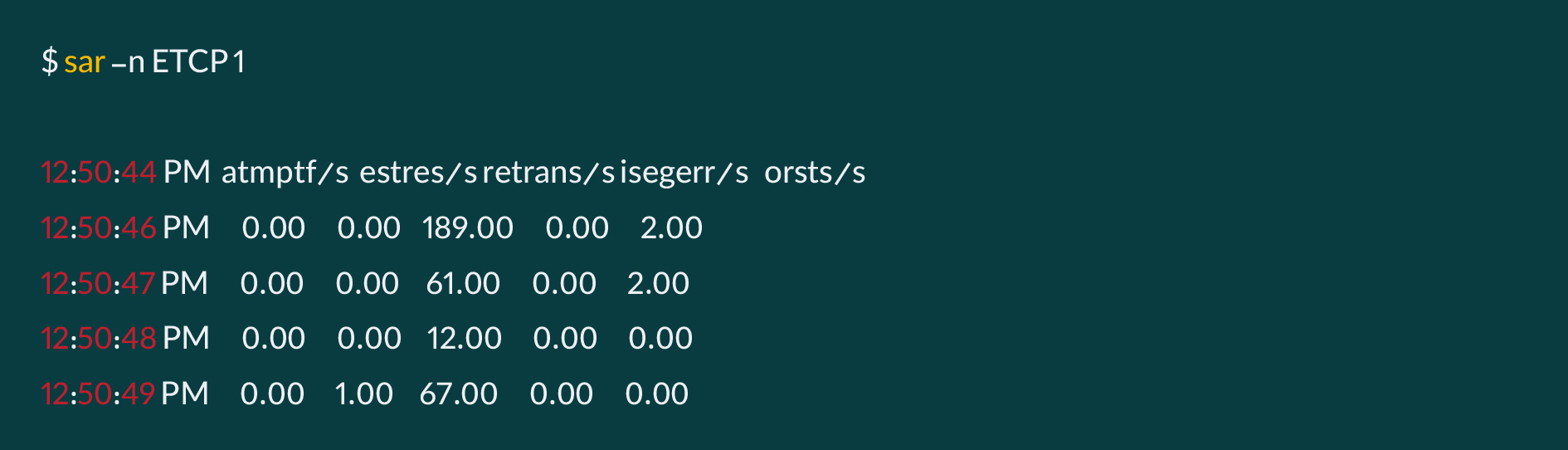
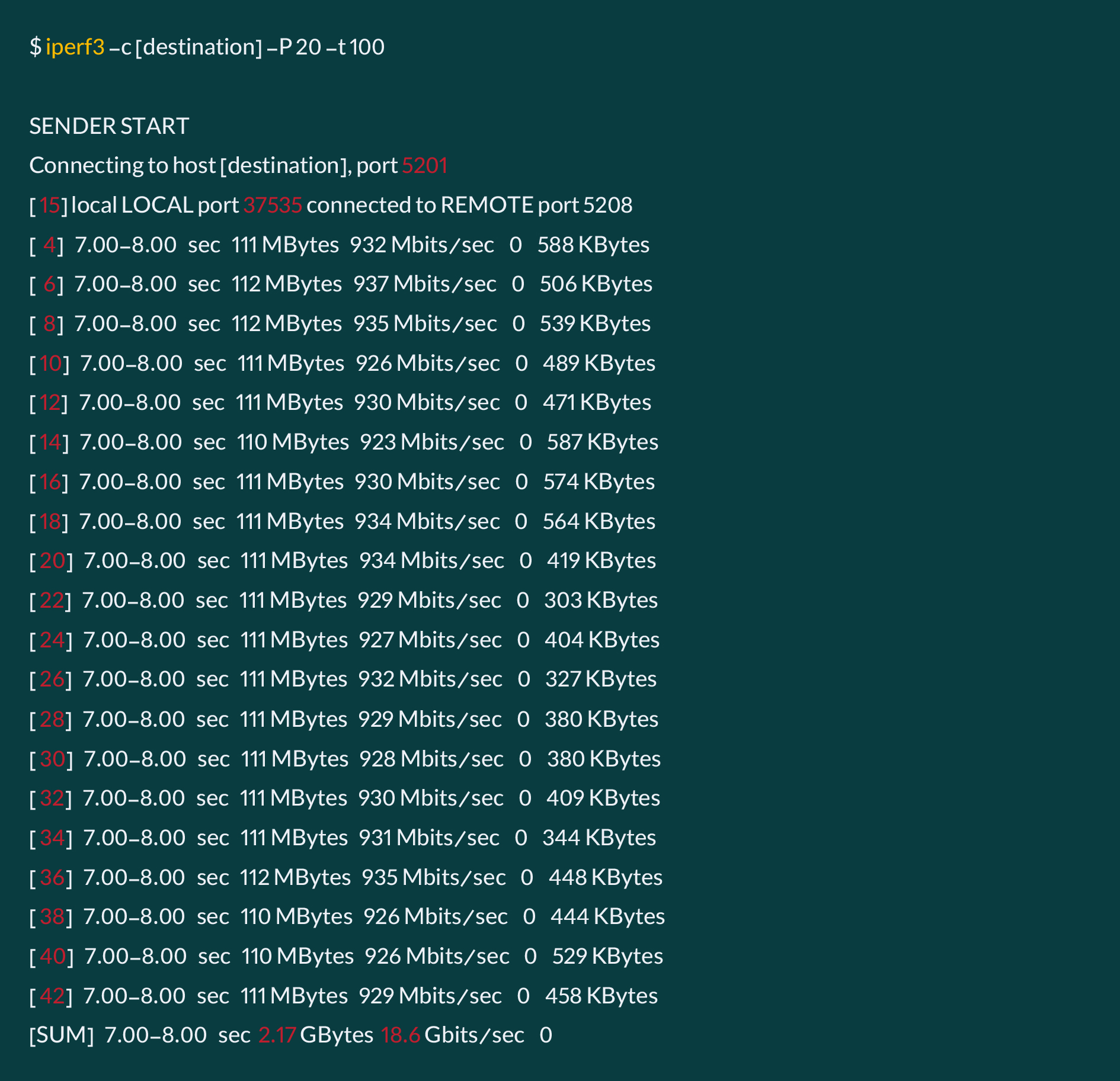
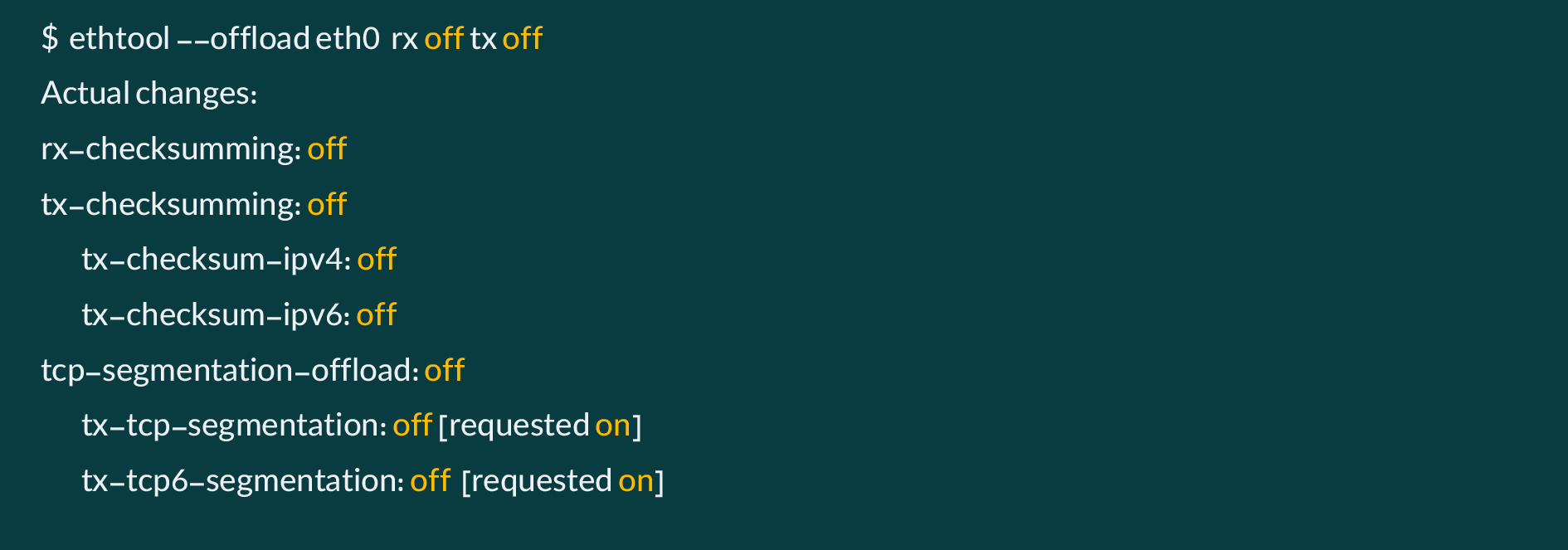
معمولن در توصیههای مربوط به بهبود و کاهش TCP Retransmission پیشنهاد میشود، کیفیت ارتباطات فیزیکی، فیبر و SFP مورد توجه قرار بگیرد، اما در موقعیت ابر آروان، مشکل از این بخشها نبود و دو اصلاح مهم کمک کرد که TCP Retransmission کاهش یابد. در مجموع باید تلاش کرد همواره این عدد کمتر از ۳درصد از کل پکتهای رد و بدل شده در واحد ثانیه باشد.
این دو اصلاح، یکی بهروزسانی firmware کارتهای شبکه و مورد مهمتر خاموش کردن فرآیند checksum روی کارت شبکه در هنگام ارسال و دریافت ترافیک بود:
https://www.kernel.org/doc/html/latest/networking/checksum-offloads.html
بهبود تنظیمات کلاستر Ceph
بخش مهمی از اقدامات انجام شده تلاش برای بهینهسازی تنظیمات Ceph و تغییر گامبهگام متغیرها در لحظات مختلف و با توجه به شرایط مختلف بود.
همانطور که توضیح داده شد برای پایدار شدن کلاستر Ceph و اصلاح وضعیت PGها که منجر به پایداری دسترسی به اطلاعات میشود، کلاستر باید در وضعیت ریکاور قرار میگرفت، اما مشکل اصلی زمانی رخ میداد که چند دقیقه پس از قرار گرفتن کلاستر در وضعیت ریکاور، OSDها شروع به down و up شدن میکردند و این OSD flapها مهمترین عامل ناپایداری و عدم بهبود وضعیت PGها و Objectها بودند. این چرخهی معیوب همواره ادامه داشت و کلاستر نمیتوانست مقاصد مطمین و پایداری برای دسترسی به اطلاعات و ایجاد یک نقشهی مطمین از وضعیت PGها و Objectها را در خود بسازد.
با توجه به اینکه این اتفاق پس از رفتن به حالت ریکاور اتفاق میافتاد، نخستین حدس ما در دامنهی سرویس Ceph، بالا بودن مقدار op/s و اعداد پیشفرض ریکاور بود. ما حدس زدیم با توجه به اینکه کلاستر تغییرات کلانی در وضعیت PGها و OSDهای خود دیده است، شاید یکی از پارامترهای مربوط به مقدار backfilling یا recovery بالاست که منجر به exhaust شدن OSDها و restartشدنشان میشود. بهسرعت از این موضوع اطمینان پیدا کردیم و دوباره تمامی این اعداد را در حالت کم و پایین قرار دادیم:

پس از اطمینان از این موضوع، دقت و تمرکز را روی اعداد recovery گذاشتیم تا ببینیم op/s و recovery throughput روی مقدار کمی باشد. خروجی ceph -s همین موضوع را به ما نشان میداد. op/s و سرعت بازیابی بسیار پایین آماده بود اما ارتباطی با کم کردن فشار روی OSDها و Flap شدنشان نداشت.

در این موقعیت سعی کردیم با بررسی OSDهایی که در این مدت Flap شدند، تلاش کنیم ببینیم آیا میتوانیم به یک الگوی خاص و مشخص برسیم؟ در اینباره، موارد مختلف را بررسی کردیم؛ پراکندگی این OSDها محدود به سرورهای خاص نمیشد، هیچ ارتباطی بین درصد utilization این OSDها و نسبت Flap شدنشان وجود نداشت و…
سعی کردیم رفتار یک OSD خاص را هدف قرار دهیم و آن را بهطور دقیق بررسی کنیم.
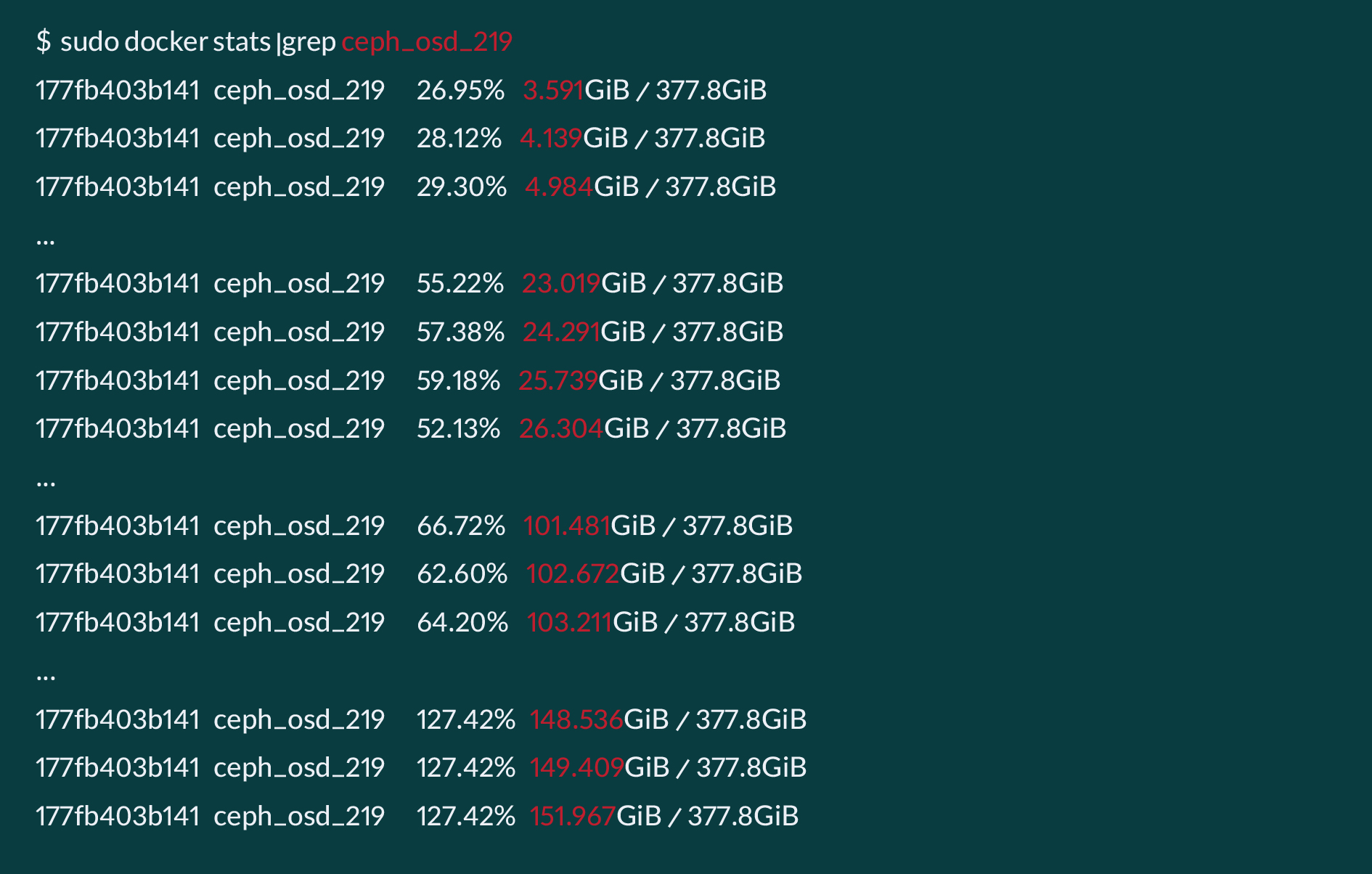
چیزی که برای ما نمایان بود این بود که چند دقیقه پس از استارت شدن OSD، مصرف Memory آن OSD کمکم افزایش پیدا میکرد و این موضوع آنقدر ادامه مییافت که تمام RAM سرور پر شود. در این وضع، زمانیکه تمامی RAM سرور اشغال میشود، OOM Kill اتفاق میافتد و OSD Process را terminate میکند.
OOM Kill چیست؟
در سیستمعامل وضعیتی به نام Out Of Memory و فرآیندی به نام Out of Memory Killer برای محافظت کرنل سیستمعامل وجود دارد. هنگامیکه مموری بهشکل کامل با یک یا چند Process مصرف شود، این خطر وجود خواهد داشت که سیستمعامل بهطور کامل Crash کند و سیستم از دسترس خارج شود، کرنل برای محافظت از خود این فرآیند را آغاز میکند و فرآیندی که بیشترین مصرف Memory دارد را Kill خواهد کرد. بهطور مشخص، بروز این اتفاق سبب Killشدن ناگهانی OSD و در نتیجه Flap شدن آنها و ناپایدار کردن فرآیند این بازیابی میشود. این موضوع کلاستر را وارد یک حلقهی معیوب میکند و بهبود وضعیت کلاستر را متوقف میکند.
https://www.kernel.org/doc/gorman/html/understand/understand030.html
در این موقعیت سعی کردیم دو موضوع را بسیار سریع امتحان کنیم.
نخستین مورد بررسی پارامتر osd_memory_target بود که مقدار رم اختصاص داده شده به OSDها را در کلاستر تعیین میکرد. در کلاستر این مقدار را برابر با ۴ گیگابایت برای هر OSD تعیین کرده بودیم. با توجه به اینکه بسیاری از OSDها مصارفی نزدیک به این عدد داشتند، برای تست، موقت این مقدار را on the fly با injectargs به مقدار ۸ گیگابایت رساندیم.
دومین مورد، امتحان کردن memory limit روی کانتینر OSDها بود. این موضوع را بسیار سریع با گرفتن runlike از چند OSD container برای نمونه و اعمال hard limit روی memory آنها انجام دادیم. اعمال این محدودیت نیز تاثیری در مشکل Memory Leak نداشت، چون با بیشینه شدن مصرف Memory هر Container اتفاق مشابه داخل آن تکرار میشود و OOM_Killer رفتار مشابهی را انجام خواهد داد.
پس از مشخص شدن این خروجیها، با همفکری سعی کردیم تا مواردیکه به نظرمان بهطور مستقیم بر مصرف Memory روی OSDها تاثیر دارد را شناسایی و سپس اقدامات لازم برای کاهش مصرف Memory آنها را انجام دهیم.
نخستین گام ما برای بهینهتر کردن مصرف رم OSDها، تغییر در مقدار PG Log بود. هر نوع تغییر در وضعیت PGها و هر نوع transaction log در سطح کلاستر به عنوان PG Log روی OSDها ثبت میشود. ثبت این وقایع به Ceph کمک میکند تا به هنگام بازیابی با بررسی این لاگها با سرعت بسیار بالاتری بازیابی کند. اما با توجه به شرایط کلاستر که همواره OSDها در حال flap هستند و mapping مربوط به PGها همواره در حال تغییر است، ما حدس زدیم که احتمالن حجم بسیار بالایی از رم را PG Logها و ثبت این وقایع استفاده میکنند. این موضوع را با استفاده از گرفتن dump_mempool از چند OSD که در لاگ flapبرای آنها ثبت شده بود، ارزیابی کردیم:

سپس مقدار pg_log_entries را برای این بازه از مقدار ۱۰۰۰۰ به ۵۰۰ کاهش دادیم.

در گام بعدی باید مطمین میشدیم که این حجم از PG Logهایی که تا به آن لحظه روی OSDها ثبت شدهاند با اعمال این تغییر، حتمن سبکتر میشوند و عملیات PG log trimming روی آنها اعمال میشود. برای این کار مقدار threshold مربوط PG log trimming روی هر OSD را بهطور دقیق برابر با مقدار PG log entries قرار دادیم:

پس از اعمال این تغییرات روی تمامی OSDها، انتظار داشتیم تا فرآیند PG log trimming روی OSDها آغاز شود. پس از کمی انتظار و ارزیابی دقیق وضعیت چند OSD، برخلاف انتظار ما هیچ تغییری روی PG Logها اتفاق نیفتاد و هیچ فرآیند trimming روی هیچ OSDیی شروع نشد. کمی بیشتر بررسی کردیم و متوجه شدیم با توجه به وضعیت کلاستر و مقدار درخور توجه PGهای غیر active/clean، هیچ کدام از پارامترهای PG log و PG log trim در این موقعیت روی کلاستر اعمال نمیشوند.
در این موقعیت با توافق داخلی و بررسی جوانب مختلف تصمیم گرفتیم تا PG Log تمامی OSDهای کلاستر (بیش از صدها OSD) را بهشکل offline و دستی trim کنیم.
برای این کار باید بسیار محتاط عمل میکردیم؛ سرور به سرور و OSD به OSD جلو میرفتیم تا کمترین فشار به کلاستر، آن هم در این شرایط، وارد شود. برای اطمینان از این موضوع باید تمامی تمهیدات لازم برای جلوگیری از بازیابی، جابهجایی PG و هر پردازش اضافی روی کلاستر را متوقف میکردیم. مطمین شدیم تمامی فلگهای زیر در این بازه حتمن روی کلاستر اعمال شدهاند:

سپس اسکریپتی نوشتیم تا بهترتیب با iterate روی تکتک سرورها و OSDها، این فرآیند را بهطور manual روی آنها و PGهای آنها اعمال کند. در قلب این اسکریپت دو عمل مهم انجام میشد. گرفتن فهرست PGهای قرار گرفته روی OSD مقصد و انجام فرآیند PG log trim روی آن PGها.

با اینکه این فرآیند تمام خودکار بود و بهکمک اسکریپت انجام میشد، اما این فرآیند زمان بسیاری از ما گرفت. برخی OSDها بسیار سریع بین یک تا دو دقیقه ولی برخی OSDها تا ۳۰ دقیقه فرآیند PG log trimشان طول میکشید. چون احتمال میدادیم این فرآیند بین ۱۲ تا ۲۴ ساعت طول بکشد، اجازه دادیم این فرآیند بهشکل جداگانه انجام شود و ما بهطور موازی همچنان به بررسی دقیقتر مشکل و موارد دیگر بپردازیم.
جلوگیری از OOM Kill شدن OSDها
در این مدت متوجه شدیم سه OSD مشکل جدی پیدا کردهاند و استارت نمیشوند. با بررسی اولیه لاگهای آنها، متوجه شدیم که rocksdb آنها corrupt شده است، با خطای Compaction error: Corruption: block checksum mismatch مواجه میشوند و امکان initialize اولیه را ندارند. نمونه ای از این خطا بهشکل زیر است:

عمل force termination که سیستمعامل برای فرآیند OSDها بهدلیل پر شدن حافظه ایجاد میکرد، موجب آسیب زدن به rocksdbهای مربوط به OSDها میشد. برای جلوگیری از آسیبدیدگی OSDهای بیشتر، تصمیم گرفتیم با نوشتن یک اسکریپت ساده که از اجرای پیوستهی آن بهکمک Monit یا هر Daemon مشابه بشود اطمینان پیدا کرد، وضعیت Memory را بهشکل پیوسته روی OSD Serverها را چک کنیم، و اگر از یک بیشینهای افزایش پیدا کرد، Container مرتبط با OSD دچار مشکل شده را Restart کند. مهمترین تفاوت این restart دستی این است که پردازش OSD بهشکل graceful stop میشد که از تخریب ساختار OSD و محتوای آن جلوگیری میکرد.

- افزایش سرعت عملیات Trim روی Snapshotها
درخواستهای Trim برای Snapshotهای PGها در یک صف به نام snap trim queue قرار میگیرند، کلاستر در وضعیتی قرار داشت که صف snap trim queue بسیار شلوغ بود و نیاز داشتیم تا هر PG که در وضعیت Clean قرار میگیرد بسیار سریع پردازش شود و از صف خارج شود. ما سرعت این فرآیند را با افزایش اولویت و افزایش همزمانی بهبود دادیم.

متغیرهای مربوط به timeout فرآیندهای بازیابی و Suicide را افزایش دادیم:

- بررسی و رفع Bottleneckها
تمام نودهای کلاستر ذخیرهسازی، تمام OSDها و در گام بعدی PGها مورد بررسی دقیق قرار گرفت. یکی از نودها بهدلیل داشتن IRQ بالا بهشکل کامل از مدار خارج شد. سپس گامبهگام شروع به از مدار خارج کردن OSDهایی کردیم که Latency بالاتر نسبت به میانگین کلاستر داشتند.
- افزایش فشار تدریجی روی کلاستر
از طریق افزایش گامبهگام سه متغیر مهم max_backfill, max_active، همچنین اولویتدهی به فرآیند بازیابی از طریق متغیر recovery_op_priority فشار روی کلاستر را افزایش دادیم.
- نکته: در نظر داشته باشید که این تغییرات بهدلیل شرایط کلاستر و افزایش سرعت بازگشت به حالت استفاده است و برای کلاستر در حالت عادی توصیه نمیشود.

- متغیرهای sysctl
ابر آروان برای کلاستر ذخیرهسازی خود از نسخهی Lowlatency کرنل استفاده میکند. با این وجود از تنظیم سراسری برخی از پارامترهای کرنل برای قرار گرفتن در حالت Lowlatency باید اطمینان پیدا کرد. برای نمونه، در فرآیند بازیابی، تعداد بالایی کانکشن TCP بین سرورها برقرار و بسته میشود. در این فرآیند تعداد بسیار بالایی کانکشن در وضعیت TIME_WAIT قرار میگیرد و سبب میشود سیستم در وضعیتی قرار گیرد که کانکشن جدیدی نتواند باز کند.
تنظیمات مربوط به TCP را در حالت زیر قرار دادیم:

همچنین مهم است متغیرهای Network Buffers و Connections در حالت بهینه قرار بگیرند:

مقدار vm.min_free_kbytes را هم از قبل، برابر با یک گیگابایت قرار داده بودیم تا کرنل همیشه یک گیگابایت فضای آزاد Memory برای سیستم نگه دارد.

- اطمینان از خاموش بودن Connection Tracking
برای درگیری کمتر networking stack سرورها، مطمین شدیم connection tracking برای ارتباط بین سرورهای استوریج غیرفعال است.

وصلهی کد Ceph برای حل مشکل مدیریت مموری
کلاستر ذخیرهسازی در دیتاسنتر IR-THR-AT1 از نسخهی ceph-v12.2.13 استفاده میکند، با مشاهدهی رفتاری شبیه به مموری لیک، ایشوترکرِ ceph بهدقت مورد بررسی قرار گرفت، بهبودهای مرتبط به Memory Leak در نسخههای دیگر مورد بررسی قرار گرفت. یکی از مشکلات گزارش از یک اشکال مرتبط به memory pool برنامه در مشکل شماره 46027 بود:
https://tracker.ceph.com/issues/46027
bufferlist c_str() sometimes clears assignment to mempool
Sometimes c_str() needs to rebuild underlying buffer::raw.
It that case original assignment to mempool is lost.
این تغییر روی نسخهی 12.2.13 انتقال پیدا کرد، اما تاثیر مهمی روی کلاستر نداشت.
سه نشانهی مهم سبب شد، روشن شود که مشکل پیشآمده مربوط به memory fragmentation است:
- رفتاری که در موردِ مموری دیده میشد، نشان میداد که کرنل امکان آزادسازی مموری را ندارد، در حالیکه خود برنامه (کانتینرهای OSDها) هیچ استفادهای از فضای مموری اشغال شده نداشتند.
- به هنگام رخ دادن مموری فرگمنتیشن، allocation زمانبر خواهد شد و برنامه کند میشود. کند شدن ceph و مشکلی که در ارتباط با OSDها دیده میشد تاییدکنندهی اختلال در allocation بود.
- در فرآیندِ بازیابی، تعدادِ بالایی allocation کوچک نیاز خواهد بود. در نتیجه در وضعیت ویژهی کلاستر، سیستم بهشدت مستعد memory fragmentation بود.
در نسخههای بعدی (ماژور آپدیتها که در شرایط DR امکان مهاجرت به آن وجود نداشت، برای جلوگیری از memory fragmentation تغییرات مهمی داده شد، از جمله میتوان به تغییر زیر اشاره کرد:
https://github.com/ceph/ceph/pull/25077
common: drop append_buffer from bufferlist. Use simple carriage instead #25077
در اقدامات بعدی تلاش شد، تمام کامیتهای مرتبط به موضوع در نسخهی ۱۶ در نسخهی ۱۲ سازگار و ارایه شود.
حرکت کلاستر بهسمت بهبود
با مجموع اقدامات انجام شده، کلاستر در وضعیت مناسبتری قرار گرفت، تیم فنی تصمیم گرفت با تنظیم مجدد Flagها کلاستر را در وضعیت Recover قرار دهد. از ساعت ۱۸:۰۰ روز سهشنبه ۳ فروردین ماه وضعیت کلاستر بهسمت بهبود حرکت کرد.

در این نمودار رنگ سبز افزایش Placement Groupهای Clean و رنگهای نارنجی و آبی به ترتیب کاهش Placement Groupهای Degraded و Undersized را نشان میدهد و بهمعنای حرکت کلاستر بهسمت پایداری است. حدود ۴۸ ساعت زمان برد، تا نزدیک به ۱۰۰درصد از Placement Groupها در حالت Clean قرار بگیرند:


در طول این مسیر براساس وضعیت تمام سرورها و OSDها چندبار فرآیند ریکاور شدن متوقف و دوباره از سر گرفته شد. همچنین برخی از OSDها از مدار خارج شدند، برخی کاهش یا افزایش وزندهی شدند، خطاهای برخی از OSDها برطرف و همچنین با انتقال دادههای برخی از Placement Group ها به سایر بخشها، PG دارای اشکال حذف شدند.
از بامداد روز جمعه وضعیت کلاستر بهشکل طبیعی خود برگشت و امکان دسترسی Read/Write پرسرعت ابرکها روی کلاستر ذخیرهسازی فراهم شد.









2 دیدگاه
خیلی خوبه که گزارش کامل و دقیق پایدارسازی رو دادید ، به امید پیشرفت روزافزون ابرآروان
درود
متشکریم از شما.